System Design Overview
Databases
MongoDB
Snapcaster uses MongoDB to store over 4 million in stock cards sold in Canada, 50,000 Oracle ID’s of card base names used for the auto complete service, and a card set collection that automatically updates after being scraped every single day.
PostgreSQL
PostgreSQL’s relational database is used for mapping our user account information, subscriptions, LGS vendor data, and time stamps for analytics.
Redis
Redis caching helps speed up common queries, which helps takes the load off our MongoDB Servers and our catalog service’s /search endpoint. Our /websites and /sets endpoint in the search service also takes adavantage of Redis caching since it’s loaded on every page load for all users.
Snapcaster API
Snapcasters back-end uses a micro service architecture and is written using Fast API (Python) and Express (JavaScript) Rest API’s. A more detailed breakdown can be found under Services section.
Search Service Endpoints (Fast API)
The Search service was our first microservice used to handle many of our card search queries and is slowly being phased out. Currently Snapcaster still reli
/health
/sets
/websites
/advanced (This is being depreciated soon and integrated into the catalog service)
User Service Endpoints (Express)
The User service handles everything account related ranging from creating an account, resetting passwords, maintaining user sessions and so on. It uses JWT tokens to create and maintain user sessions.
/health
/register
/login
/forgotPassword
/updateUser
/profile
/auth/discord
/auth/discord/disconnect
/auth/discord/callback
/refresh
/test-access-token
/test-refresh-token
/verify-email/:token
/reset-password
/verify-email/:token
/resend-verification-email
Catalog Service Endpoints (Express)
The Catalog service is a middleware service that implements pagination and caching user queries. This is especially important for the wish list service since users can load up to 100 saved queries at once which can negatively affect performance.
/search
/search_multiple
Auto-Complete Service Endpoints (Express)
Textbox auto complete recommendations are based on the cards Oracle ID (Base card name) since one card can have many different printings. This is stored in a cards collection in MongoDB. When a user starts typing in the search bar, the /cards endpoint performs a text index search on MongoDB’s Oracle ID collection and returns recommended auto fill suggestions.
/cards
Payments Service Endpoints (Express)
Snapcaster uses Stripe for the payment service. This way, all we have to do is setup a webhook, which means the responsibility of handling user payment information is taken care of by Stripe at the cost of a 12% transaction fee.
/webhook
/createCheckoutSession
/createPortalSession
Analytics Service Endpoints (Express) (Depreciated)
Seperate from the data quality analytics that checks for document count and uniquness across our MongoDB collections, this service is used for tracking user trends and behviours when querying for cards on Snapcaster. (This isn’t currently used for anything at the moment since we migrated it to our snapcaster-analytics repo)
/buy-clicks
Wish List Service Endpoints (Express) (Depreciated)
Wish List allows users to create, update, delete custom card wish lists.
Wish List Routes
/create
/update/:id
/delete/:id
/user
/items/:id
/view/:id
/:id/bulk
Wish List Items Routes
/wishlist-item/create
/wishlist-item/update/:id
/wishlist-item/delete/:id
Scrapers
Snapcasters 71 supported websites can be broken into 5 categories based on what platform they use to host their front and back-end: Face To Face, Conduct Commerce, Crystal Commerce, and Shopify.
Shopify platforms can use an array of back end inventory management systems including:
Face To Face and Conduct Commerce websites are run using two synchronous pyhton scripts run by scheduled cron jobs.
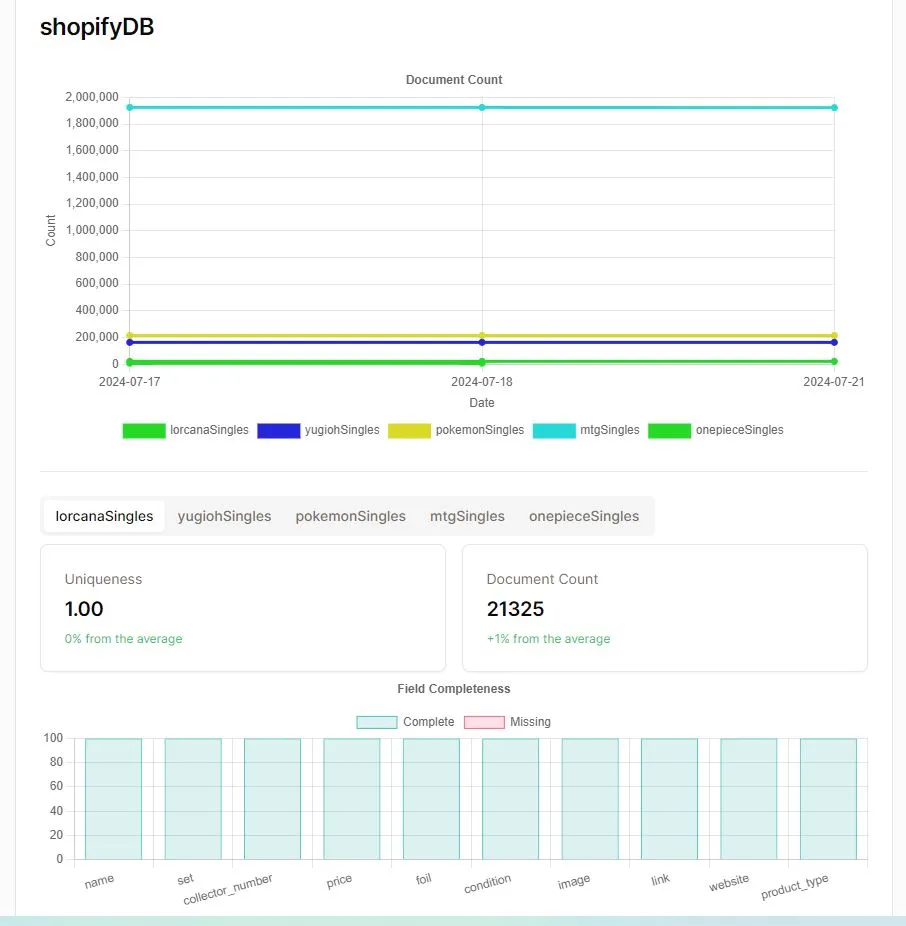
In order to ensure data integrity, Snapcaster has a scraper analytics service that determines data quality based on the percentage of unique entries (Ensuring there is no duplicate data). This can be viewed on the vendor dashboard website if you’re logged in as a product owner.
Railway (Cloud Hosting Platform)
Snapcaster uses Railway’s cloud infrastructure platform to host it’s databases, micro services, and cron jobs. It’s cheap, secure, and easy to keep track of costs with Railways server utilization reports. The biggest convience is being able to share access to all of the services and their variables between each other instead of spending time configuring AWS IAM roles.
Vercel
Since NextJS was created by Vercel, we just use their web hosting service. Some of the benifits include using NextJS and Vercel specific tags in our front end code which is better optimized on their platform. Snapcasters NextJS configuration is set to use ReactJS, TypeScript, Tailwind CSS, and Shadcn UI.
Docker (Local Development)
We use Docker to ensure that our coding environments are consistent when developing in a group environment. Our Docker Compose file automatically spins up a container and runs an initialize script to setup each micro service and database container:
- Nginx reverse proxy container
- Search service container
- Catalog service container
- User service container
- Payment service container
- Auto complete service container
- MongoDB server container
- Postgres server container
- Redis server container
- Analytics container (Depreciated)
- Wishlist service container (Depreciated)